14. KAFKA : Kafka Theory More...






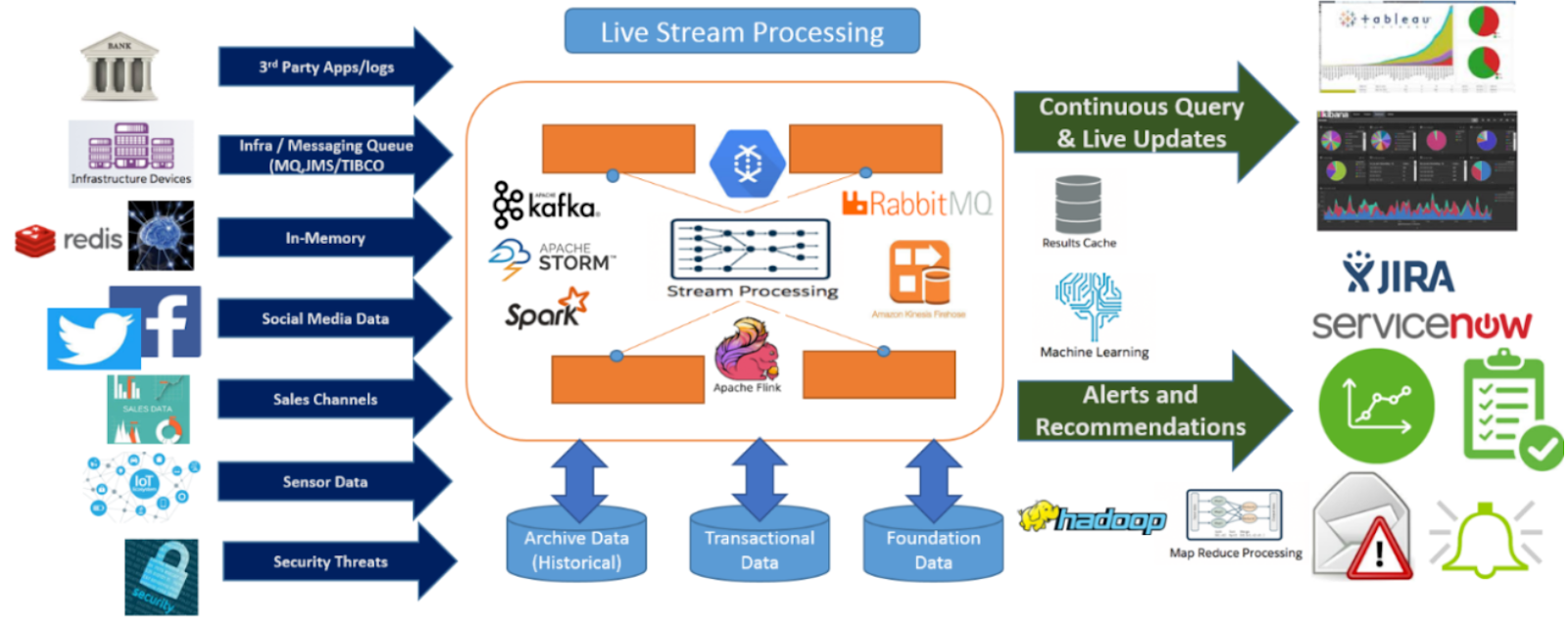


- runs on its own cluster
Other Messaging systems
------------------------------------
Msgs sending --> kafka store on multiple m/c
JMS -> not distributed
Flume - once msg comes always it write to HDFS
Producer consumer
----------------------------
Database
Application
Receiever
-----------
Requirement : Campturing the streamm:
Expectation : Reciver must run all the time
Data processing
Normal Spark Receiver/Flume:
---------------------
Normal Spark Receiver runs on commodity hardware, if it goes down one more comes but by that time no one is there to capture the coming data
Normal spark receiver - if data coming rate is high it will burst (same thing happened with indian railway)
Runs on one m/c(JVM), but we can run 2 Reciver, but both receive the data, there will be duplicate copies and uses more resource
If Receiver configure for every 5 sec, process should happen with in that so that it can take another, but if process itself takes 10 sec then ...
Kafka/Rabit-MQueue:
---------------------
Kafka -
Its not Master/slave
Falult tolarance : Replication of messages
what ever msg we send backend it will be stored in binary as file system
Able to handle millioins of message per sec easily (linked in get millions per sec)
Stream processing is available (Kafka confluent) : Later kafka started giving Kafka processing engine also (same like spark)
Retension: by default it preserve the streams for 7 days, and preserve in array of bytes, message will not be removed irrespective of consumer consumed or not, once retension comes then only it will removed
- retension time is over
- retension size is over
Messages (csv,txt,avro...)
Header
----------
Body
1 Tweet (1msg should convert to Byte Array) -> Kafka(Recieve always as Byte array) -> Stream -----> Poll (Time : 100ms, size: 100kb)
If message size is > 100kb => will throw error, so that we need to increase message size
If message size is < 100 kb => other message also come with that
Every Instance of kafka is called => Broker
Every broker should have unique id (eg: B0, B1, B2)
Every broker should have unique IP:Port (eg: IP:9092, IP:9093, IP:9094)
As of now there is NO limitation for number of brokers
Producer1 send message(Topic-"sales") -> will go to Queue(Partition) internally store as file
Producer2 send message(Topic-"sales") ->
Zookeeper => keeps the count of Broker, Broker sends ping to zookeeper server (Heart beat time : Tick tok)
In Kafka => Zookeeper is mandatory, and it comes 1st before broker starts (means we have to start the zookeeper 1st then kafka/broker server)
heart beat could be in mili sec also
Znode - How zookeeper maintain all broker is : every object maintain in zookeeper called Znode
eg : If zookeeper is mainintainig 3 borkers, then 2 Znodes
Znode - Broker0(Id), Lastupdate,
Znode - Broker1(Id), Lastupdate,
Znode - Broker2(Id), Lastupdate,
Kafka => Min Java 1.6
Images###########
export http_proxy=www-proxy.us.oracle.com:80
export https_proxy=www-proxy.us.oracle.com:80
wget www.google.com
wget http://www-us.apache.org/dist/kafka/2.2.1/kafka_2.12-2.2.1.tgz //download kafka directly in Workstation
kafka_2.13-2.4.0\config
zookeeper.properties //zookeeper can be downloaded independent also
dataDir=/tmp/zookeeper //(default store in /tmp folder) - Physically maintain all Znode informations...
clientPort=2181 //on which port zookeeper is running...
server.properties //every broker one server.properties will be there
broker.id=0 //mandatory: unique broker should be there, minimum property
listeners=PLAINTEXT://:9092 //9092 is the port produceer and consumer can communicate
log.dirs=/tmp/kafka-logs
log.retention.hours=168
log.segment.bytes=1073741824 //if segment reaches this size then go that segment to one file | | | | |
#################################################
//Start zookeeper & kafka server
cd kafka_2.12-2.2.1
bin/zookeeper-server-start.sh config/zookeeper.properties
bin/kafka-server-start.sh config/server.properties
bin/kafka-topics.sh --zookeeper localhost:2181 --list
//Below command will fail bez replication factor is > number of brokers
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic MyFirstTopic --partitions 3 --replication-factor 2
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic MyFirstTopic --partitions 3 --replication-factor 1
bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic MyFirstTopic
//increasing the partition for particular topic
//we cannot decrease the partition
//even when producer/consumer running we can increase the partitions
bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic MyFirstTopic --partitions 5
For testing - console based Producer/Consumer
---------------------------------
Terminal-1 (Producer)
--------------------
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic MyFirstTopic
Terminal-2 (Consumer)
---------------------
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic MyFirstTopic
#################################################
for Every parttion there is a leader selected, only leader will get and give on demand
Eg: if 3 borkers are there
partition0 -> 1 Leader(Brok2), 2 followers
partition1 -> 1 Leader(Brok1), 2 followers
partition3 -> 1 Leader(Brok3), 2 followers
Kafka => the order of message consumer receives will not be in same order, but producer receives in correct order
Kafka monitoring tool => just to monitor what is there in Kafka partition
Producer has choice want acknoledge -> Leaders read
- 0 : Fast : (Fire and forget)
- 1 : Slow: (If Leader reads fine, then Leader writes 1)
- All : Slowest : (If Leader reads fine, write to Lea-der and followers then Leader writes All) - Banking sector
Ways to Send message from Producer
Topic : "MyMessage"
---------
Message - Hello
Message - India, Hello
key.hashcode % no of partition
100 % 4 = 0 -- will go to Partition P0
Pak, hello
40 % 4 = 1 -- will go to Partition P1
Nepal, hello
40 % 4 = 1 -- will go to Partition P1
Message - K, V, P#
Message - K, V, P#, TS
Consumer maintains below 2 offset, so that for next reading cosumer can ask...
############################################
1> Read offset
2> Commit offset
Status of Broker is maintained by zookeeper

https://drive.google.com/file/d/1iode3dT2ziL5d0pxoA_294plrUDh6twv/view?usp=sharing

Kafka (Distributed messaging system)
#####################################
- Independent tool nothing to do with HDFS- runs on its own cluster
Other Messaging systems
------------------------------------
Msgs sending --> kafka store on multiple m/c
JMS -> not distributed
Flume - once msg comes always it write to HDFS
Producer consumer
----------------------------
Database
Application
Receiever
-----------
Requirement : Campturing the streamm:
Expectation : Reciver must run all the time
Data processing
Normal Spark Receiver/Flume:
---------------------
Normal Spark Receiver runs on commodity hardware, if it goes down one more comes but by that time no one is there to capture the coming data
Normal spark receiver - if data coming rate is high it will burst (same thing happened with indian railway)
Runs on one m/c(JVM), but we can run 2 Reciver, but both receive the data, there will be duplicate copies and uses more resource
If Receiver configure for every 5 sec, process should happen with in that so that it can take another, but if process itself takes 10 sec then ...
Kafka/Rabit-MQueue:
---------------------
Kafka -
Its not Master/slave
Falult tolarance : Replication of messages
what ever msg we send backend it will be stored in binary as file system
Able to handle millioins of message per sec easily (linked in get millions per sec)
Stream processing is available (Kafka confluent) : Later kafka started giving Kafka processing engine also (same like spark)
Retension: by default it preserve the streams for 7 days, and preserve in array of bytes, message will not be removed irrespective of consumer consumed or not, once retension comes then only it will removed
- retension time is over
- retension size is over
Messages (csv,txt,avro...)
Header
----------
Body
1 Tweet (1msg should convert to Byte Array) -> Kafka(Recieve always as Byte array) -> Stream -----> Poll (Time : 100ms, size: 100kb)
If message size is > 100kb => will throw error, so that we need to increase message size
If message size is < 100 kb => other message also come with that
Every Instance of kafka is called => Broker
Every broker should have unique id (eg: B0, B1, B2)
Every broker should have unique IP:Port (eg: IP:9092, IP:9093, IP:9094)
As of now there is NO limitation for number of brokers
Producer1 send message(Topic-"sales") -> will go to Queue(Partition) internally store as file
Producer2 send message(Topic-"sales") ->
Zookeeper => keeps the count of Broker, Broker sends ping to zookeeper server (Heart beat time : Tick tok)
In Kafka => Zookeeper is mandatory, and it comes 1st before broker starts (means we have to start the zookeeper 1st then kafka/broker server)
heart beat could be in mili sec also
Znode - How zookeeper maintain all broker is : every object maintain in zookeeper called Znode
eg : If zookeeper is mainintainig 3 borkers, then 2 Znodes
Znode - Broker0(Id), Lastupdate,
Znode - Broker1(Id), Lastupdate,
Znode - Broker2(Id), Lastupdate,
Kafka => Min Java 1.6
Images###########
export http_proxy=www-proxy.us.oracle.com:80
export https_proxy=www-proxy.us.oracle.com:80
wget www.google.com
wget http://www-us.apache.org/dist/kafka/2.2.1/kafka_2.12-2.2.1.tgz //download kafka directly in Workstation
kafka_2.13-2.4.0\config
zookeeper.properties //zookeeper can be downloaded independent also
dataDir=/tmp/zookeeper //(default store in /tmp folder) - Physically maintain all Znode informations...
clientPort=2181 //on which port zookeeper is running...
server.properties //every broker one server.properties will be there
broker.id=0 //mandatory: unique broker should be there, minimum property
listeners=PLAINTEXT://:9092 //9092 is the port produceer and consumer can communicate
log.dirs=/tmp/kafka-logs
log.retention.hours=168
log.segment.bytes=1073741824 //if segment reaches this size then go that segment to one file | | | | |
#################################################
//Start zookeeper & kafka server
cd kafka_2.12-2.2.1
bin/zookeeper-server-start.sh config/zookeeper.properties
bin/kafka-server-start.sh config/server.properties
bin/kafka-topics.sh --zookeeper localhost:2181 --list
//Below command will fail bez replication factor is > number of brokers
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic MyFirstTopic --partitions 3 --replication-factor 2
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic MyFirstTopic --partitions 3 --replication-factor 1
bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic MyFirstTopic
//increasing the partition for particular topic
//we cannot decrease the partition
//even when producer/consumer running we can increase the partitions
bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic MyFirstTopic --partitions 5
For testing - console based Producer/Consumer
---------------------------------
Terminal-1 (Producer)
--------------------
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic MyFirstTopic
Terminal-2 (Consumer)
---------------------
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic MyFirstTopic
#################################################
for Every parttion there is a leader selected, only leader will get and give on demand
Eg: if 3 borkers are there
partition0 -> 1 Leader(Brok2), 2 followers
partition1 -> 1 Leader(Brok1), 2 followers
partition3 -> 1 Leader(Brok3), 2 followers
Kafka => the order of message consumer receives will not be in same order, but producer receives in correct order
Kafka monitoring tool => just to monitor what is there in Kafka partition
Producer has choice want acknoledge -> Leaders read
- 0 : Fast : (Fire and forget)
- 1 : Slow: (If Leader reads fine, then Leader writes 1)
- All : Slowest : (If Leader reads fine, write to Lea-der and followers then Leader writes All) - Banking sector
Ways to Send message from Producer
Topic : "MyMessage"
---------
Message - Hello
Message - India, Hello
key.hashcode % no of partition
100 % 4 = 0 -- will go to Partition P0
Pak, hello
40 % 4 = 1 -- will go to Partition P1
Nepal, hello
40 % 4 = 1 -- will go to Partition P1
Message - K, V, P#
Message - K, V, P#, TS
Consumer maintains below 2 offset, so that for next reading cosumer can ask...
############################################
1> Read offset
2> Commit offset
Status of Broker is maintained by zookeeper

No comments:
Post a Comment